INTELLITHING
![]()
INTELLITHING is the enterprise LLM Operating Layer that unifies infrastructure, compute, and compliance into a single foundation, enabling global companies to safely adopt and scale AI across their business with a declarative-first approach.
By automating infrastructure, optimizing resources, and enabling effortless scaling, INTELLITHING empowers users to build, deploy, and run generative AI workflows without the complexity or high costs typically associated with such processes.
Key Principles
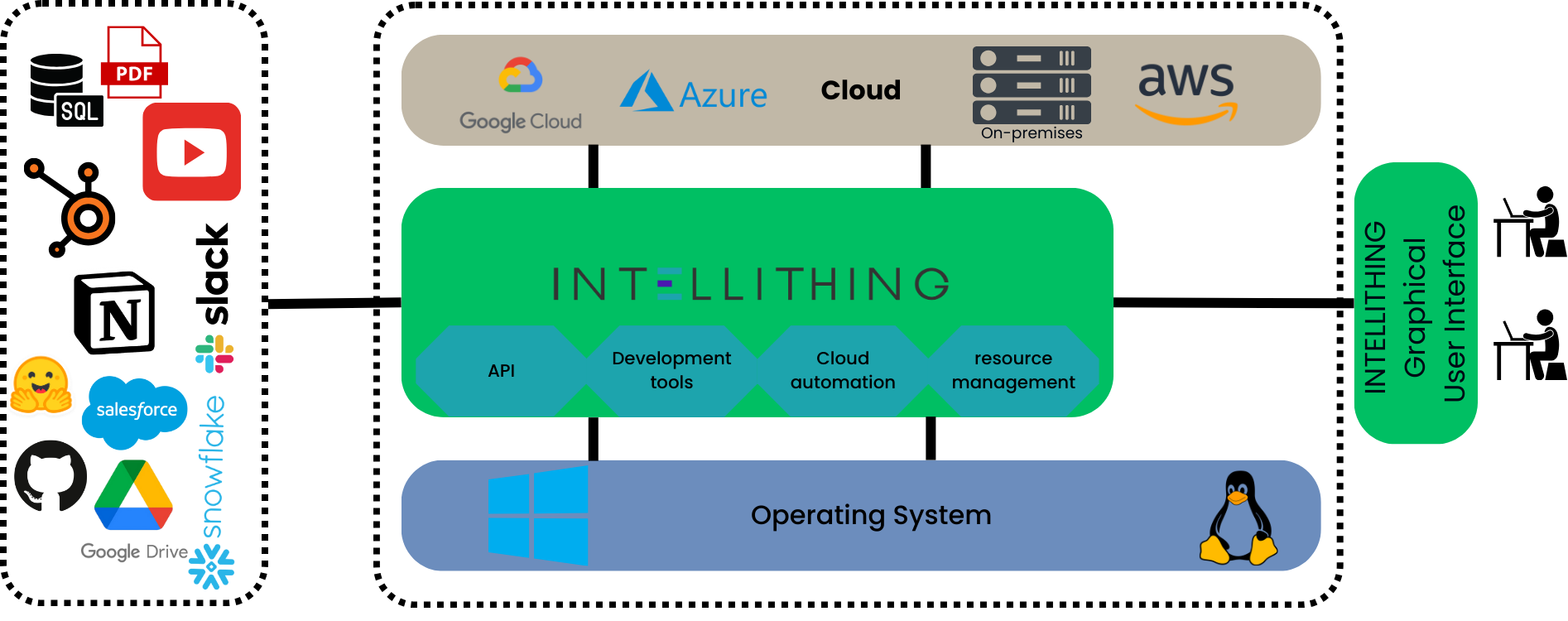
- Cloud Native: INTELLITHING utilises cloud native tools such as Kubernetes and is compatible with almost all cloud providers.
- Production Grade: INTELLITHING is built for the development and deployment of production ready products with Stability, Reliability, Maintainability, Faster recovery from failure in mind.
- No vendor lock-in: The end products can be migrated out of INTELLITHING by clicking a single button.
- Compliance and security at heart: We are fully compliant with SOC 2 and ISO 27001 frameworks.
- Declarative-first design: Workflows and apps are defined in portable, version-controlled configurations, ensuring reproducibility and auditability.
- Graphical Interface: Configurations are rendered visually, making workflows accessible to both technical and business users.
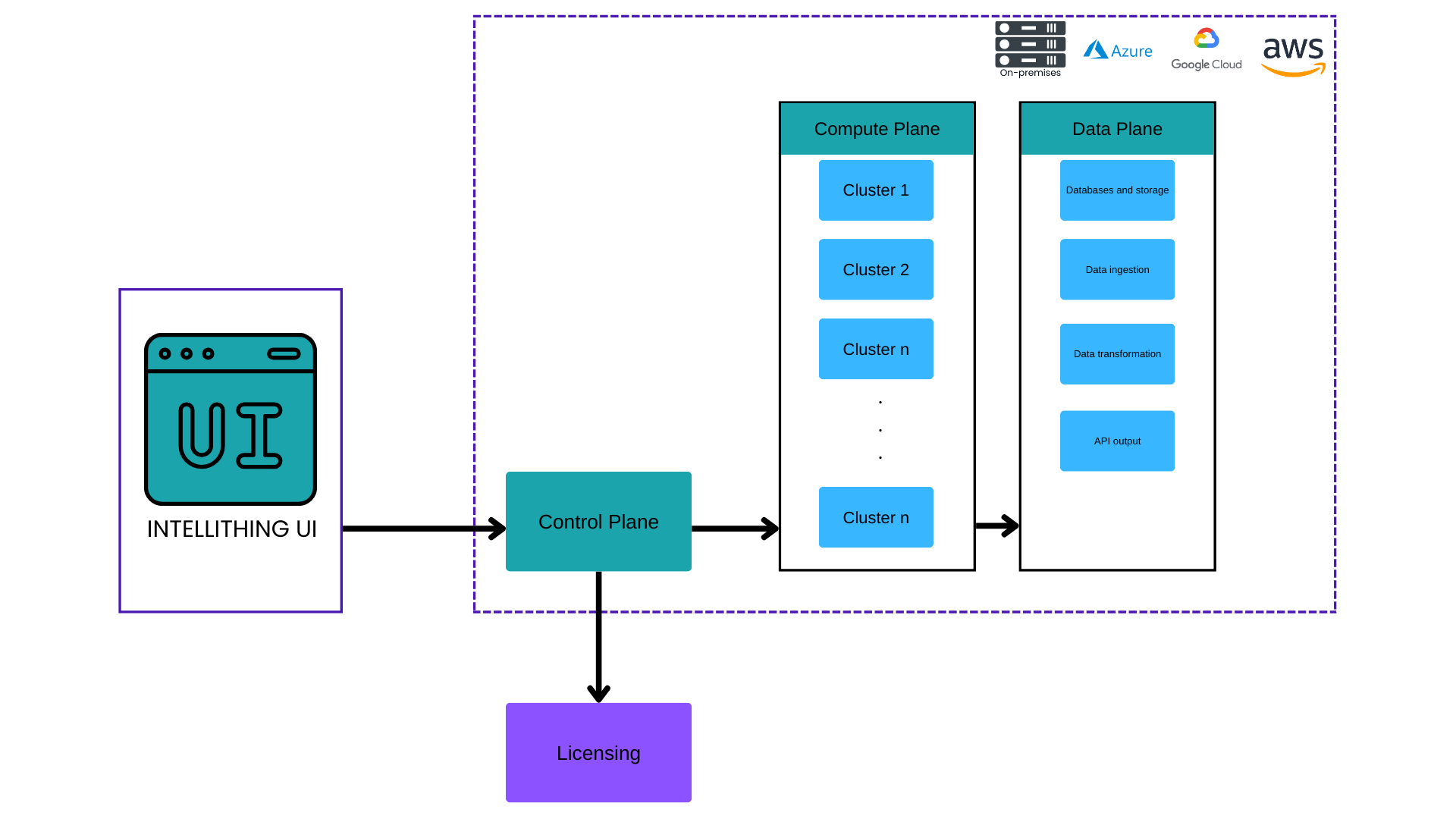
- Unified orchestration: INTELLITHING orchestrates resources across the stack from low-level runtime resources to high-level infrastructure and services, transforming LLM application development, deployment, and infrastructure management into a seamless, compliance-first orchestration.
Key Features
- Train a Model: With INTELLITHING AutoML you can easily train a supervised model in a no code yet powerful visual editor. INTELLITHING automates the entire ML pipeline — from data preprocessing and model selection to hyperparameter optimisation, ensembling, model explainability, infrastructure, and resource management during training and deployment.
- Synthetic Data Generation: Takes care of synthetic data generation, modeling, evaluation, privacy metrics, and fairness testing — all within a unified framework.
- Studio: A full fledged powerful visual editor that enables building of enterprise grade workflows using Hugging Face compatible LLMs, supervised models, agents, and data connectors. With Studio you can deploy any workflows and INTELLITHING will handle infrastructure management, low level operating system resource management, and inference optimisation as well as security and API endpoints.
- Evaluators: Built in evaluation techniques for testing deployments and workflows.
- Monitoring and Alerts: INTELLITHING takes care of monitoring of the pipelines, hardware usage, and deployment performance in a simple analytics UI.
- Simple Integration: INTELLITHING is known for its simple AI/ML integration. Simply connect your data sources and internal/external software to your AI/ML workload and format input and output with ease.
Conceptual Architecture
Technical Architecture
Contact Information
For more details or to schedule a demo, visit INTELLITHING's official website.